Clustering and Association Rules for Web Service Discovery and Recommendation: A Systematic Literature Review
Abstract
Context
Exponential growth in the volume and variety of Web services poses challenges to Web service discovery and recommendation. To address these challenges, a myriad of data mining techniques for Web services have been proposed over the last decade.
Objective
To identify, summarize and systematically compare various clustering and association rule techniques for Web service discovery and recommendation, identify the most common datasets used in the extant literature, and highlight current trends and future research directions.
Method
We follow the methodology of Kitchenham [1] for a systematic literature review (SLR). A set of research questions are designed. Six digital databases are searched. A total of 4,581 papers were initially retrieved, and a rigorous two-stage scanning process resulted in 66 relevant papers. Based on the selection criteria and data extraction, 57 final studies were selected. These papers are summarized and compared, and the relevant information is extracted to answer the research questions.
Results
The synthesis resulted in knowledge of currently proposed methods for Web service discovery and recommendation based on clustering and association rule techniques. Furthermore, this review identifies algorithms, similarity measures, evaluation metrics and datasets. This study also identifies challenges, research gaps, trends and future directions. We propose a classification of Web service discovery and recommendation methods and map the 57 final selected papers into these classes.
Conclusion
This review will help researchers to understand the current state of the art in clustering and association rules techniques for Web service discovery and recommendation and also recognize trends and future directions for improvement. Future studies should broaden the basis of discovery and recommendation by including various types of Web service descriptions including plain text that are currently used in Web APIs. There is also an opportunity for improvement by utilizing modern techniques based on big data analytics and social network analysis.
Keywords
Systematic literature review, Web service discovery, Web service recommendation, Clustering, Association rules
Introduction
Web services constitute the foundational building blocks of service-oriented architectures (SOAs) for the creation of software applications in a distributed computing paradigm [2]. Web services are a set of loosely coupled software components that are developed, described, published, discovered, used, and reused to achieve explicit functionalities [3]. There are different types of Web services, which provide different functionalities over the Internet. They include Simple Object Access Protocol (SOAP)-based, Representational State Transfer (REST)-based, eXtensible Markup Language-Remote Procedure Call (XML-RPC)-based and JavaScript Object Notation (JSON)-RPC-based Web services. The most popular forms are REST-based and SOAP-based Web services. Recently, enterprises leverage their assets by widely publishing their Web services or application programming interfaces (APIs), allowing scaling of their functionalities over the Internet and the use of different business models. With the growing number of Web services, the demand for discovery and recommendation mechanisms for Web services has also increased.
Web service discovery is the process of finding and locating existing Web services based on the service requester's requirements. It must match services' functional and non-functional descriptions [4,5], as well as retrieve Web service descriptions e.g., Web services description language (WSDL) and Web application description language (WADL) published by a service provider. The functional requirements refer to the elements that indicate the system's capabilities. Functional characteristics of Web services include interfaces, operations, and protocol bindings. These are typically described in the service profile [5,6]. Non-functional requirements refer to the elements that indicate the system's performance parameters, which may include quality of service (QoS) considerations, and service policies (e.g., security features and service cost) [5,6].
Web service recommendation systems assist Web service consumers in the process of Web service selection where QoS parameters play a significant role in ranking Web services [7]. Because many Web services have similar functionalities, the service requester must perform service selection without prior knowledge regarding the list of Web service candidates. Web service recommendation systems provide leverage by suggesting and ranking Web services to help service requesters during the selection process. Web service recommendation systems have been used to improve Web service discovery systems in different studies.
Data mining and machine learning techniques have been used to improve the process of Web service discovery and recommendation. More specifically, clustering and association rule techniques are used to boost the discovery and recommendation of Web services. Clustering algorithms are used to cluster Web services into different clusters to minimize the search space of Web services based on various similarity measures. Furthermore, association rule algorithms are used to find the relationships and correlations between services and users to build a recommendation model.
This SLR aims to identify, explore, summarize and synthesize clustering and association rule techniques used for Web service discovery and recommendation. The final objective is to provide the reader with the current state of clustering and association rule techniques utilized in the process of Web service discovery and recommendation by identifying the methods, algorithms, similarity measures, datasets and evaluation metrics. Furthermore, this SLR aims to understand and demonstrate whether there are algorithms, datasets and similarity measures that are used much more frequently compared to others. The motivation and the need to conduct this SLR are explained as follows:
• The discovery problem is inherently difficult because of the large scale of SOA systems. This includes Web services, which are dynamic, changing, and uncertain in nature. The scope of services in SOA changes rapidly as services are added and removed or modified. Developers abandon older standards as new standards emerge. Web service discovery and recommendation are critical to the success of Web services because such services are useless if users cannot discover them;
• The use of Web services in the industry is gaining attention. This allows developers to efficiently use, discover, and select Web services through discovery and recommendation systems. Thus, it is critical to identify techniques that facilitate Web service discovery and recommendation;
• Data mining, text mining, and machine learning techniques provide solutions to facilitate the process of Web service discovery and recommendation where clustering, classification, and association rule algorithms have been applied. The focus of clustering and association rules is based on the identification of algorithms, similarity measures, datasets, and evaluation metrics. These favour the building of practical Web service discovery and recommendation systems. This helps future researchers to make sense of the Web service discovery and recommendation landscape regarding the use of clustering and association rules;
• Over the past decade, several clustering and association rule techniques for Web services have been proposed to facilitate the process of Web service discovery and recommendation. Thus, there is a need to investigate the characteristics and details of such techniques using a systematic method and quality requirements; and
• Data mining and analytics is a quickly evolving field, and this SLR provides useful information and synthesis regarding the current state of Web service discovery and recommendation research using clustering and association rule techniques, particularly due to the lack of comprehensive SLR in this area.
• The remainder of the paper is organized as follows. Section 2 provides background regarding Web services and the need for discovery and recommendation. In Section 3, we describe the research method indicating the search selection, data extraction, quality assessment and evaluation strategies and the SLR phases. In Section 4, we report the results of this study by analysing the final selected papers and providing answers to the research questions. Section 5 presents our discussion and observations. Section 6 discusses possible threats to the validity of this SLR. Finally, we conclude the paper in Section 7 by summarizing some of the outcomes of this study.
Background
Web services are enabling technologies for E-Business that provide fast, efficient and reliable services to customers over the Internet [8]. Web services are self-contained, modular applications with business functionality and logic that are described, published, located, discovered and invoked over a network on the World Wide Web. Most Web services are described using the standard WSDL or according to the REST paradigm [5]. However, service providers publish their Web services' functional descriptions in different languages and formats. According to [5], seekda.com, which was a web portal for publishing Web services, reported 30k Web services in November 2011. It is also reported by the public directory website programmableweb.com (PW) that it has approximately 16k single or composite RESTful Web services as of March 2013 [5]. The numbers of Web services rapidly increased the number of places where Web service providers publish their services, including public directories, Web portals, and API Marketplaces, in various languages and formats.
The process of locating existing Web services based on the service requester's functional and non-functional requirements [4,5] and retrieving the Web service descriptions previously published by a service provider is known as Web service discovery. The standard discovery mechanism for SOAP-based Web services is the use of Universal Description, Discovery, and Integration (UDDI), which is an XML-based registry that provides service providers with the ability to publish and register their Web services by providing their specifications. UDDI is used to provide Web services with a way to be discovered by service consumers based on keyword matching [9]. There is no discovery standard for REST-based Web services. The discovery process starts with Web service providers advertising their Web services in Web service repositories by publishing their Web service description (e.g., a WSDL file). In the Web service data layer [10], service providers share their service data (web service descriptions and specifications, which can be in different formats) to be stored for any inquiry from service users. Services' potential users send a request to query (keyword-based if UDDI) the repositories at the Web service data layer by specifying their Web service requirements. The service matcher matches the request with the available Web services and recommends a set of Web services that match the requester's needs. The final step is the selection and invocation of the best Web service that meets the user's needs.
Specialized search engines, including Titan, Seekda, and Wooglea, provide an advanced solution to Web service discovery. However, most Web service search engines rely on keyword-based matching. Therefore, the search may suffer from a lack of keywords in the description. Web service files do not contain an adequate number of words for index terms or features. Moreover, the small numbers in the Web service files are erratic and unreliable [11]. The limited number of functionalities offered by Web services can lead to insufficient terms in descriptions, which differs from regular text documents. Furthermore, a huge and irrelevant number of Web services will be returned due to a broad search space. Clustering Web services based on similarities can minimize the search space [12].
Approaches to Web service recommendation help in understanding the user's requirements when selecting a Web service. Although Web service recommendation is challenging and time-consuming due to large search spaces, clustering techniques can minimize this space [13]. QoS information plays a major role in Web service recommendation, and when it is limited, Web service recommendation approaches usually either fail to make predictions or make inferior ones. However, QoS information is hard to obtain because users often request very few of the available Web services [14]. Furthermore, it is impractical, costly, and time-consuming for users to try all candidate Web services and acquire QoS information [14-16]. Due to user disparity, QoS values evaluated by one user cannot be directly employed by another for Web service recommendation. Therefore, it is necessary to either identify associations between users or cluster users based on their similarities.
Web service technology is an efficient and effective way to deliver services to users in E-business and E-commerce. Companies across the globe use Web services; they develop and publish such services to leverage enterprise business models. However, the Web services concept is unfamiliar to end users who continue to struggle in discovering and selecting the appropriate Web services. End users need advanced mechanisms to assist in the discovery and selection of services. This has led many researchers to propose solutions to enhance Web service discovery and recommendation. Data analytics, text mining, information retrieval, and machine learning techniques provide solutions to facilitate the process of Web service discovery and recommendation, and clustering, classification, and association rule algorithms have been applied in the field of Web service discovery and recommendation.
Research Methodology
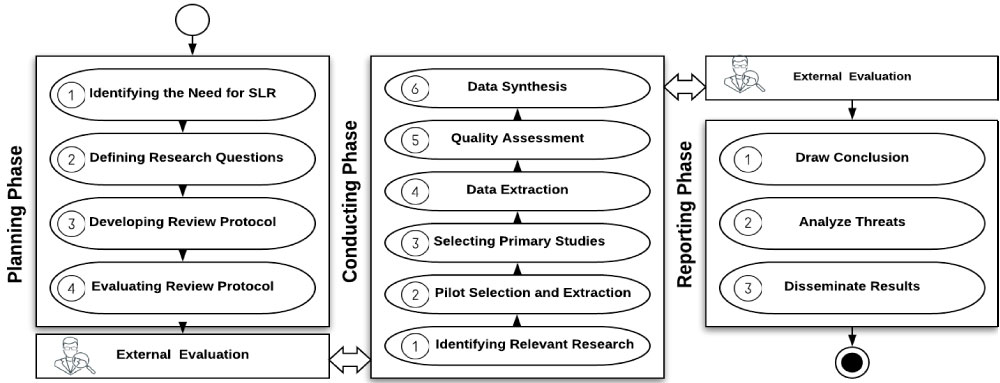
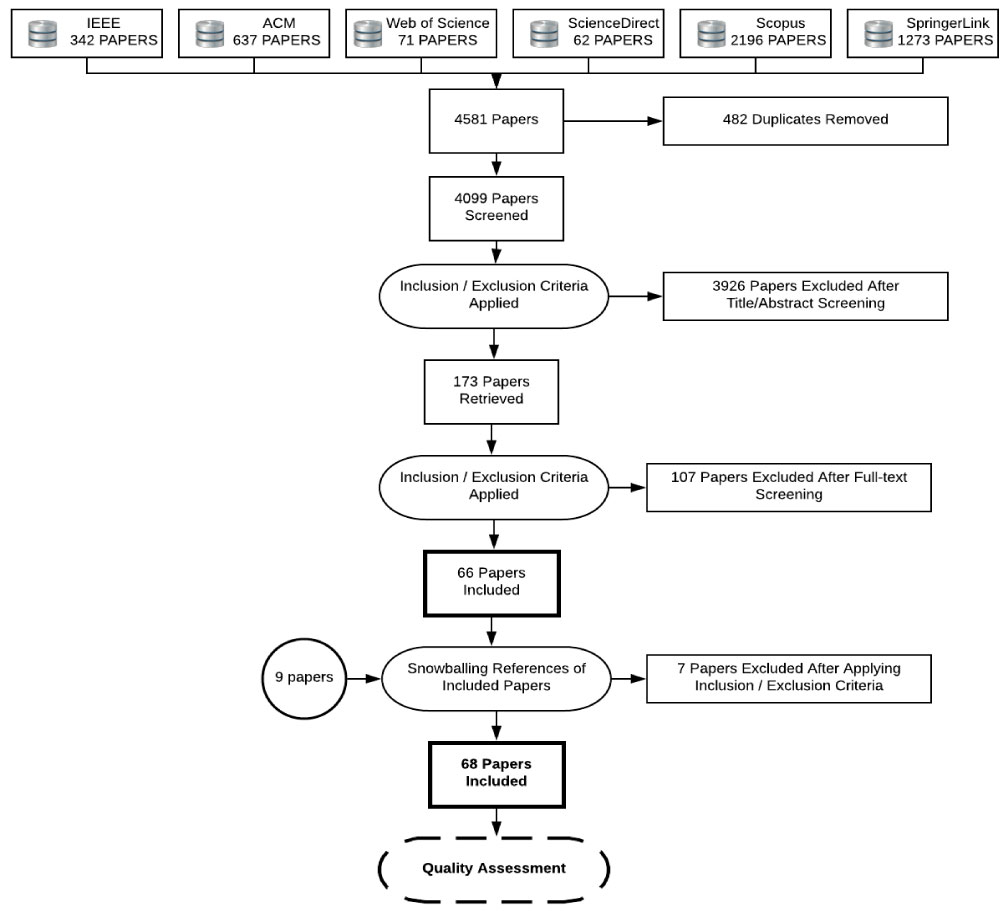
We follow general guidelines and procedures described in [1,17]. The three phases of SLR are 1) Planning, 2) Conducting, and 3) Reporting phases, as illustrated in Figure 1. The planning phase involves 1) Identification of the need for SLR; 2) Definition of research questions; 3) Development of the review protocol; and 4) Evaluation of the review protocol. Three research questions are identified following criteria acknowledged by [1]. Based on search questions and search strings, six digital databases are searched. The results retrieved 4,581 papers, which included several formats (long, short, and poster papers) and duplicates. A rigorous two-stage scanning and filtering process was followed according to predefined criteria resulted with 66 selected papers. Snowballing the 66 selected papers lead to the identification of two papers after applying the selection criteria. The 68 primary selected papers went through a quality/relevance assessment as suggested by [1,18,19]. The final activity identified 57 papers as the final selections. We collected the required information to answer the research questions, as well as analyse and summarize the results.
The planning phase
The planning phase identifies the research questions, search strategy, selection process, quality assessment, and data extraction. It also reviews protocol evaluation.
Research question definitions
We considered research questions from the viewpoints of population, intervention, comparison, outcome, and context (PICOC), as outlined in Table1. The general goal and scope of the study were formulated through PICOC. We used population and intervention in search terms and keywords. The research questions addressed include
• RQ1: What techniques, methods, and algorithms are used in clustering and association rules for Web service discovery and recommendation?
• RQ2: What are the most common datasets used to validate the proposed clustering and association rule approaches to facilitate Web service discovery and recommendation?
• RQ3: What are the trends and future research directions related to the discovery and recommendation of Web services?
RQ1 identifies:
Techniques used in the investigated studies, including clustering based on Web service discovery/recommendation or association rule-based Web service discovery/recommendation;
The proposed method to facilitate the process of Web service discovery and recommendation. Clustering and association rule techniques are used in the proposed method and supported by other techniques, such as natural language processing (NLP) and information retrieval (IR). Methods include the proposed processes/frame work used to facilitate Web service discovery and recommendation, similarity measures and evaluation matrices to validate the work; and
Clustering and association rule algorithms to support the object of the study. For example, in clustering, k-means, hierarchical and density-based clustering algorithm (DBSCAN) algorithms are employed. In association rules, the Progressive Size Working Set (PSWS) and Apriori algorithms are used.
A summary of the research questions and their motivations is listed in Table 2.
Search strategy
To avoid overlooking relevant papers, we used a generic search string, which included a broad number of articles in its initial results. We identified the search terms and keywords by following the five criteria in [1]. Based on the PICOC, we used search terms and keywords to construct search strings as follows:
(P1 OR P2 …OR Pn) AND (I1OR I2 …OR In)
Pn: Population terms, In: Intervention terms
Different spellings were considered when constructing the search string by using an asterisk (*) and the Boolean operators AND and OR. When databases allowed, the advanced search option inserted the complete search string. To extend the scope of the results, we considered the population and intervention in the search string. We included the comparison in the primary study selection process by filtering studies that did not contain methods, algorithms, datasets, and evaluation metrics. This compensated for the exclusion of the comparison in the search strings. The search string was as follows:
("Web Service*"OR"Web Service*Discovery"OR"Web Service*Recommend*")
and
("Clustering"OR"Association Rule*")
We used search strings to search six digital libraries, as listed in Table 3 along with the number of initially retrieved papers from each digital library. Search strings were adjusted according to the requirements of the selected database search engines. The search, which was conducted in 1st of February 2018, was limited to studies published between 2006 and January 2018.
Study selection process
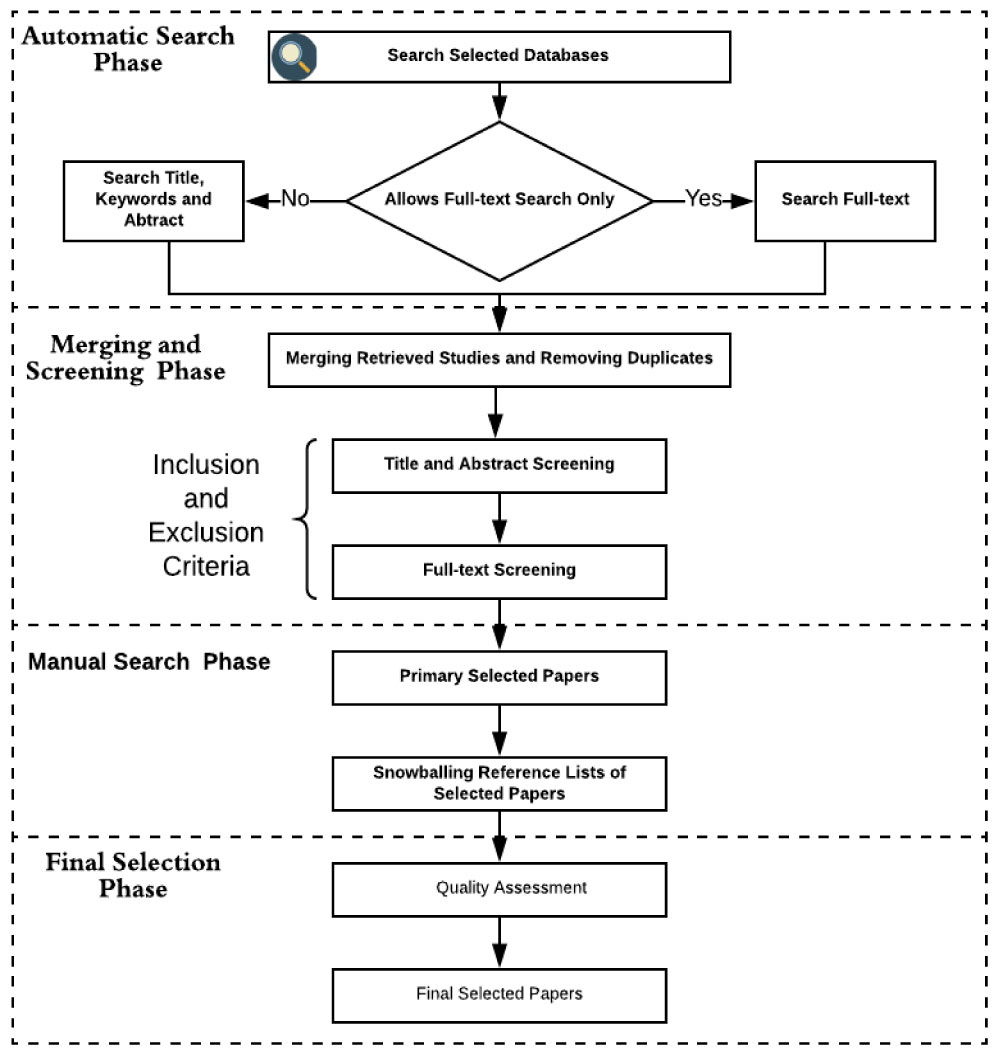
A four-phase search and selection process was used to search the digital libraries, filter the results, and collect and screen relevant papers as illustrated in Figure 2. In the first phase, an automatic search of the digital libraries was performed using search strings. In the second phase, all retrieved studies were merged after duplicates were removed. Two screening stages were performed. Title and abstract screenings were applied when the inclusion and exclusion criteria (Table 4) were checked against the titles and abstracts of the retrieved studies. The full-text screening was applied when the inclusion and exclusion criteria were checked against the full texts of the initially selected studies. In the third phase, a manual search was performed by snowballing from reference lists of the primary selected studies as recommended by [1]. In the final phase, we identified the quality of selected papers based on quality assessment criteria (Section 3.1.4).The final selectedpapers were identified based on the quality/relevance score.
Quality assessment of the primary selected studies
We used a quality assessment method based on the questions designed to assess the relevance of the selected papers. This minimizes bias and maximizes validity [1,18]. The quality assessment was a means for weighting the importance and relevance of studies during the synthesis stage of this SLR. It also supported the validity of the selected papers in this review. Based on the quality assessment questions, a numerical quantification (quality score) is assigned to rank the selected papers. This was done to help with the selection of the most related studies. It was not used as an absolute measure of a paper's quality, nor to compare the papers and the work of authors against each other. It actually indicates the relevance of the selected papers to our research questions. Based on the recommendations of [18,19], we divided the quality questions to assess general questions (GQ) and specific questions (SQ) as outlined in Table 5. The GQs focused on the quality of reporting, including the papers' rationales, aims, and context. The SQs concentrated on the technical rigor and credibility of the papers.
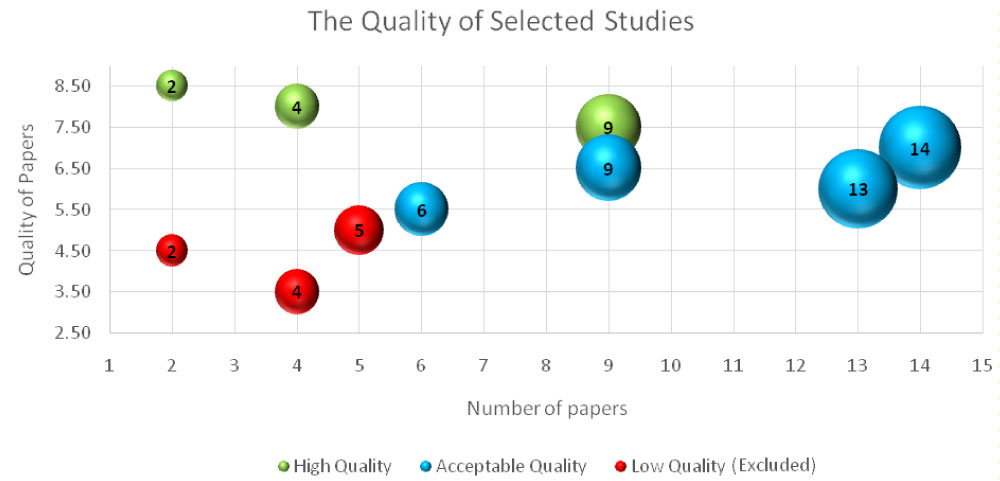
To assess quality, each paper was evaluated against GQ and SQ quality assessment questions. The answers to the questions could be "Yes," "Partly," or "No." Numerical values were assigned to the answers (1 = "Yes," 0 = "No," and 0.5 = "Partly"). The final quality score for each primarily selected paper was calculated by adding up the scores of each question. The maximum score was 9; scores of 7.5-9 represented high-quality (high-relevance) papers, scores less than 7.5 and greater than or equal to 5.5 were acceptable with average quality (relevance), and scores less than 5.5 were low quality (relevance) and resulted in exclusion. Some of the primarily selected papers were recent publications. Therefore, they were not ranked based on the number of citations.
Data extraction
This involved collecting data and information relevant to the RQs. We designed a data extraction form as outlined in Table 6. The test-retest process [1] was used to check the consistency and accuracy of the extracted data relative to the original sources. This was performed during the evaluation stage.
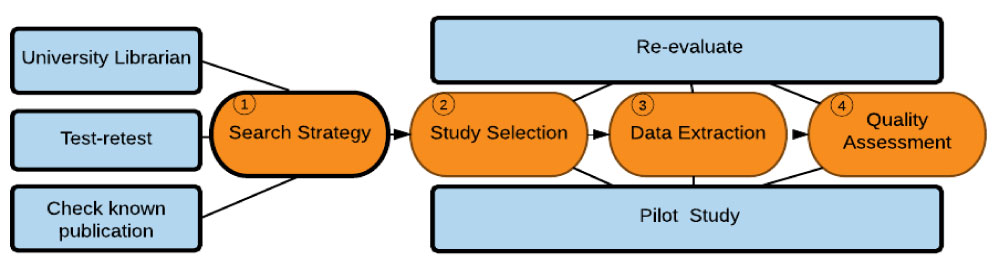
Review protocol evaluation
We confirmed that search strings were appropriately derived from the research questions. Furthermore, the search strings' effectiveness was preliminarily examined using a list of known publications [12,20,21] before using the full search. Search strings were constructed with the university librarian who had experience in working with the selected digital databases. We followed the test-retest approach to determine the final search strategy. To evaluate the study selection process, we ran and tested two stages of screening. This included title and abstract screening and full-text screening on a sample of retrieved papers with inclusion and exclusion criteria. As recommended by [1], we re-evaluated the screening stages to check the sample consistency. To evaluate quality assessment and data extraction, we performed a pilot study using a sample of the primarily selected papers to check the consistency and accuracy of the data. We confirmed that the extracted data addressed the research questions. Figure 3 illustrates the methods used in evaluating the review protocol. Furthermore, we externally evaluated the protocol before conducting the review. External experts were contacted for feedback and recommendations to refine the review protocol. Based on this feedback, we refined the review scope, improved the search strategy, and improved the inclusion and exclusion criteria.
The conducting phase
Identifying relevant research
The total number of initially retrieved papers was 4581 where a total of 482 papers were excluded due to duplications. A selection process was performed on the remaining 4,099 papers. The process proceeded with pilot selection and data extraction. All of the 4,099 papers from the digital library search process were transferred into Covidence [22]. Appendix 1A indicates the search queries for each digital library.
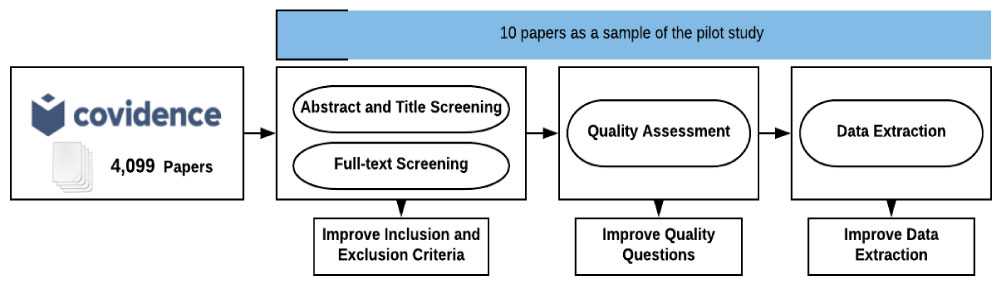
Pilot selection and extraction
Before running the selection process on 4,099 papers, we ran a pilot study to test and evaluate selection, data extraction, and quality strategies. We followed the two stages of screening, including title and abstract screening and full-text screening with Covidence. The selection process stopped at 10 papers. The data extraction and quality assessment strategies were then applied as illustrated in Figure 4. Based on this pilot study, we re-evaluated the selection, data extraction, and quality assessment strategies. We refined the review protocol based on the result of the pilot.
Selecting the primary studies
The selection process consisted of two stages to screen the remaining 4,099 papers.
Abstract and title screening: Covidence was used to screen papers by looking at keywords, filtering keywords, and applying inclusion and exclusion criteria. Based on this stage of screening, 3,926 papers were excluded. We found that some of the retrieved papers did not address Web service discovery and recommendation. For example, several papers related to biology, physics, and nature. Furthermore, some digital databases did not provide accurate results based on the chosen search strings. We excluded papers that did not explicitly address Web service discovery and recommendation. Furthermore, we excluded abstracts, posters, and short papers (less than six pages), technical reports, tutorial summaries, and books.
Full-text screening: 173 papers were scanned and 107 papers were excluded. Finally, 68 papers were selected based on the two screening stages.
Snowballing reference lists of the primarily selected papers led to the identification of nine additional primary papers. After applying inclusion and exclusion criteria, seven paperswere excluded. Two additional papers were included. Figure 5 depicts a flowchart to illustrate the selection process of the primarily selected papers, including the manually selected papers before going to the quality assessment step.
The Reporting and analysis phase
We used various factors to analyse the selected papers, and we analysed the content of the final papers to answer the research questions of this SLR.
Analysing the selected papers
Quality of the selected studies
The quality of the selected papers was identified using our quality assessment questions. Figure 6 indicates the primarily selectedpapers that successfully went through the data extraction and quality assessment process. Green bubbles provide the number of papers with high-quality scores (between 9 and 7.5). Blue bubbles provide the number of papers with average acceptable-quality scores (less than 7.5 and greater than or equal to 5.5). Red bubbles provide the number of papers with low-quality scores, which lead to exclusion (less than 5.5). The results suggest that the selected papers are of relatively average acceptable quality. 15 papers are high quality, and 42 papers are acceptable quality. Eleven papers are excluded as low quality. The list of the 57 final selected papersis provided in Appendix 1B.
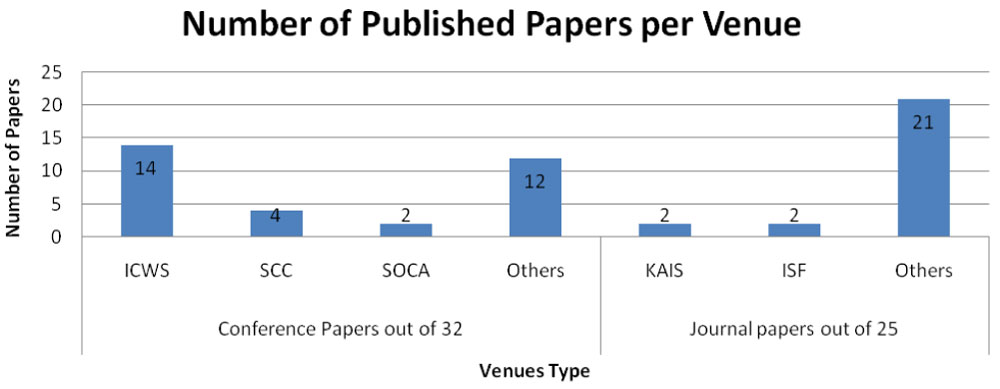
Publication venues and ranking
The types of publication venues with the number of selected papers are illustrated in Figure 7, which also shows the number of papers per venue with publication numbers equal to or greater than two. The venues, as well as their ranks and impact factors, include a list of 15 conferences and 23 journals, as outlined in Appendix 1C. The ICWS and SCC conferences are A-ranked leading conferences with 14 and 4 papers, respectively. The conference ranking is based on the Computing Research and Education Association of Australasia (CORE) [23]. CORE 2014 assigned conference categories of A*, A, B, C, and Unranked. A* refers to a flagship conference, A refers to an excellent conference, B refers to a good conference, C refers to a conference meeting minimum standards, and Unranked refers to a conference without a ranking decision [23]. We selected two articles from KAIS and ISF journals, which have good impact factors. The journal rankings rely on the impact factor reported by Thomson Reuters Journal Citation Reports [24].
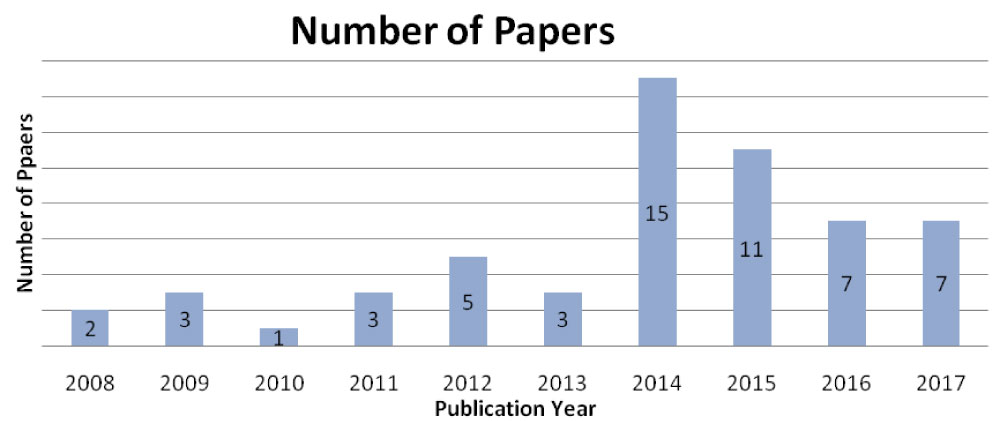
Distribution of papers over years
The selected papers that met our criteria were published in the last decade. The papers show a growing interest in this topic within the last three years. This study's search ranges from 2006 to January 2018 based on the search protocol. Figure 8, which illustrates the distribution of papers, shows that a significant number of papers were published in 2014 and 2015.
Distribution of papers by country
Table 7 outlines the distribution of papers by country. It shows that while there is a general growth in the academic literature in the area of Web service discovery and recommendation, specific research groups and authors play a major role in this growth. China has the largest number of contributions with 27 selected papers (47% of the overall selected papers). Distribution is based on the first author's country; it does not formulate a theory on the geographical allocation of teams working on Web service discovery and recommendation at the time of the review. However, it shows a growing interest in the conducted study research area from different countries and teams.
The Result of Analysing the Contents of the Final Selected Papers
In this section, we present the results of the analysis based on the contents of the final selected papers and present synthesized data to answer the research questions. We synthesized to demonstrate the classification of techniques used for Web service discovery and recommendation according to the final selected papers. This was followed by a summarization of the methods. Then, synthesized data on the algorithms, similarity measures, and evaluation metrics were discussed. Finally, we discussed the classification of datasets used, as well as future trends, directions, and research gaps.
Classification of web service discovery and recommendation techniques (RQ1)
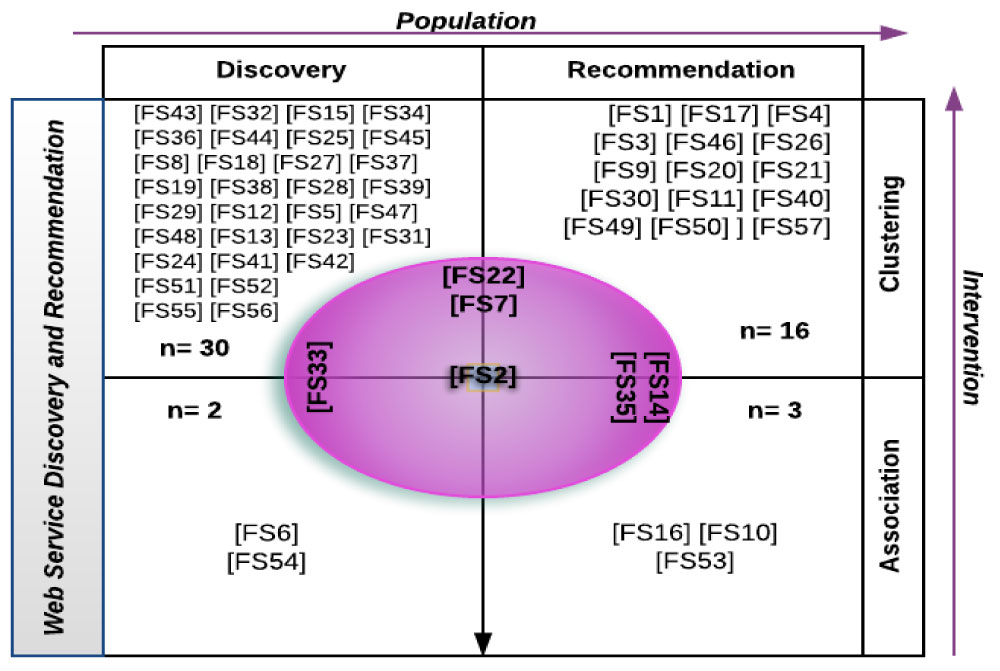
After careful analysis of the final selected papers' contents, the papers were classified into five groups given their utilized techniques to support the process of Web discovery and recommendation. Table 8 outlines the techniques used in the final selected papers, and Figure 9 illustrates the classification of papers according to the techniques.
• Clustering-Discovery: This technique refers to papers in which Web service discovery was indicated as a research problem and clustering techniques are used on Web service datasets to facilitate the process of discovery.
• Clustering-Recommendation: This technique refers to papers in which Web service recommendation was indicated as a research problem and clustering techniques are used on specific Web service datasets to facilitate the process of Web service recommendation.
• Association-Discovery: This technique refers to papers in which Web service discovery was indicated as a research problem and association rule techniques are used on specialized Web service datasets to facilitate the process of Web service discovery.
• Association-Recommendation: This technique refers to papers in which Web service recommendation was identified as a research problem and association rule techniques were used to facilitate the process of Web service recommendation.
• Combined Technique: This technique refers to papers in which both Web service recommendation and discovery were identified as research problems and clustering or association rules (or both) were used to facilitate the process of Web service discovery and recommendation.
Methods for web service discovery and recommendation (RQ1)
The methods proposed by researchers to facilitate the process of Web service discovery and recommendation can be categorized as illustrated in our classification in Figure 9. 53% of the selected papers used clustering to minimize the search spaces of Web services by clustering similar Web services using different similarity measures and clustering algorithms. 28% of the selected papers used clustering to support the process of Web service recommendation by clustering similar users or similar Web services to facilitate the process of selection and recommendation. Two selected papers used association to support the process of Web service discovery. Three papers used association to support the process of Web service recommendation. Finally, 11% of the selected papers used clustering or association rule to support the combined process of Web service discovery and recommendation.
In the following sections, we synthesize the final selected papers based on our classification of the methods, providing more details about the used methods and their specifications. In each sub-section, we present a table which lists the clustering algorithms used, features and specifications of the proposed method, the type of Web service description language used, and whether the proposed clustering is based on functional or non-functional properties of web services.
Methods based on clustering for Web service discovery
Table 9 provides a summary of the clustering methods for Web service discovery by stating their algorithms, specifications, datasets used and whether it uses functional or non-functional properties. To enhance the performance of Web service clustering and address the drawbacks of limited service data being available for clustering, [FS32][FS12] used K-means clustering and NLP for functional-based Web service clustering after incorporating auxiliary long texts from Wikipediab with corresponding Tags to learn from the set of data and improve clustering. Tag-aided dual Author Topical Model (TD-ATM) on short text from PW was used in [FS32] and [FS12] in a Dual Tag-aided Latent Dirichlet Allocation (DT-LDA) method based on transferring learning from auxiliary long text data from Wikipedia to enrich the service data obtained from PW. For the same reason, [FS36] used Hierarchical Agglomerative Clustering (HAC) and WordNet in a crawler-based system to gather Web service descriptions and functionally cluster them. NLP is used for WSDL feature extraction, and noun phrases are discovered from vectors for tagging services. Furthermore, [FS47] used k-means for functional clustering using Nonparametric Bayesian model-based Latent Functional Factors (BN-LFFs) for large-scale Web service clustering, which can learn the number of LFFs in a service space. This includes representing Web services in LFF space, identifying service LFFs and adding more information to services to improve clustering for discovery purposes.
To increase the performance of clustering using hidden semantic patterns and concepts extracted from the service description, [FS34] used HAC for an ontology learning method. Three WSDL features are extracted, an ontology is generated for each feature, similarities are captured based on domain ontology learning (logic-based reasoning) and edge court based on WordNet measures, and features are integrated and clustered. [FS44] used k-means to cluster services functionally and WordNet and Concept Net to extract concepts and semantic relations from service descriptions. It also extracts concepts from users' queries and guides users to formulate queries to return services associated with the concepts. To address the lack of semantics and scalability in Web service discovery, [FS25] used modified k-means for functional clustering and the cosine angle for the similarity between documents. The method includes two main phases to decompose service collection and match services semantically. An extensive service collection is partitioned into a set of smaller clusters. The Singular Value Decomposition (SVD) technique is applied to the cluster so that service matching against the query can be carried out at the concept level. SVD is used to extract the semantics between the user query and the service description. To overcome the time and computational complexity of logic-based semantic matching by extracting semantic, [FS8] used HAC and NLP for non-logic-based Web service discovery including matching and ranking. Correlated Topic Model (CTM) is used to extract topics from semantic service descriptions and model the correlations between the extracted topics. Based on the topic correlation, service descriptions are grouped into hierarchical clusters, and Formal Concept Analysis (FCA) formalism is used to organize the constructed hierarchical clusters into concept lattices according to their topics. By using user queries to find Web services based on keyword-based and semantic extraction, [FS42] used k-means clustering to eliminate and filter out irrelevant services based on user queries. Probabilistic Latent Semantic Analysis (PLSA) is used to capture semantics hidden behind the words in user queries and Web service descriptions. NLP, term frequency-inverse document frequency (TFIDF), cosine and Euclidean distance are used for similarity measurements.
To minimize the search space, in [FS43], a modified k-medoids clustering algorithm was used to functionally cluster similar Web services by utilizing its OWL-S semantic representation. WordNet, Levenshtein Distance (LD) and domain ontology similarity measures were used. To include more information and minimize the search space, [FS45] and [FS24] use a quality threshold clustering algorithm and normalized google distance (NGD) and NLP to extract the features of WSDL documents based on five features, and cluster Web services functionality based on integrated similarities with weights. This provides the basis for a cloud-based context-aware service discovery framework for mobile environments - Discovery as a Service (DaaS), which takes into consideration network characteristics, user preferences and context, and device profiles. To overcome the limitations of service repositories, especially with the growing size oftheir services, [FS18] used HAC to cluster web services in the repository based on their functions using distance based on semantic subsumption relations to organize services registered in the repositories into clustersfor the purpose of improve the response time, recall and precision.
To improve semantic similarity by using up-to-date knowledge and fine-grained information, [FS15] used the HAC algorithm and NLP for a context-aware similarity (CAS) method. CAS is based on a post-filtering method to increase the performance of Web service clustering using support vector machine (SVM) and domain context datasets from search engines. SVM was trained to classify domains based on terms extracted from Google and Wikipedia. To improve Web service clustering by using different similarities, [FS27] [FS37] used HAC for functional clustering, TFIDF, WordNet, and Ontology for term similarity measures in a multiphase Web service clustering method including a feature extraction phase using NLP, ontology-learning phase, similarity calculation phase, feature-integration phase and clustering phase. To overcome the limitations of semantic similarity distance measures and their thresholds, [FS31] used a technique based on a self-organizing clustering algorithm called taxonomic clustering for functionally organizing semantic Web service advertisements. A Semantic Genome Propagation Scheme (SGPS)-based ontology was used to measure the similarity between semantic concepts to semantically position Web services in the cluster space by searching the most specific parent (MSP) and the least specific children (LSC).
To reduce the drawbacks of only using features extracted from service descriptions in clustering and ignoring other words in the document, [FS19] used k-means and TFIDF for co-clustering a WSDL document and its words after extracting WSDL features using NLP and dealing with the discovery problem as a bipartite graph partitioning problem. To improve the efficiency of Web service clustering, [FS38] used Relational Data based self-Join Operation (RDBJO) to cluster Web services functionally using Ontology. Ontology technology was used to do the computation from the semantic level, and the self-join operation in RDB was used to do the calculation on the service interface and capability tables. To enhance search engine results with a list of similar services for each hit, [FS28] used HAC for functional clustering, Euclidean distance, and cosine in web-based search engines allowing Web service consumers to easily find and relate specific services to a given query. The clusters are built for results of a search query only, which limits the number of elements to a reasonable size and improves the visibility of the results. To improve REST service discovery and explore the discovery of different types of Web services, [FS39] used different types of k-means for functional clustering after using NLP for pre processing steps on WADL files, TFIDF and the Apache Lucene framework for indexing to build a Cluster Enhanced REST Service Registry (CE-RSR). Motivated by the fact that searching for the best cluster can be viewed as an optimization problem since the number of services involved in a clustering process is large, [FS23] used Particle Swarm Optimization (PSO) to functionally cluster Web services where they define the semantic similarity metrics between Web services based on the degree of match (DoM) using ontology.
To minimize the discovery time and maximize the use of Web services for business process integration within organizations, [FS29] used Partitioning around medoids (PAM) and HAC to functionally cluster Web services based on semantically similar domains using ontology. To minimize the discovery time among large service pools, [FS5] used Adbscan in the pre-clustering step using functional similarities based on ontology and process similarities going over both Web service clustering and matching. To improve the efficiency and accuracy of semantic Web service discovery, [FS48] used HAC for functional clustering, TFIDF, cosine, and WordNet for similarity measures. Four WSDL features are extracted using NLP pre-processing steps. To overcome the drawback of keyword-based discovery systems, and motivated by the fact that most Web services are in non-semantic form, [FS13] used a modified Kernel Batch Self-Organising Map (KBSOM) neural network for clustering using WordNet and latent semantics index (LSI) to represent a Web service as a service feature vector. Cosine, TFIDF, and Mahalanobis distance were used as similarity measures in the service clustering and matching process. To gather, discover, extract and integrate features from WSDL files automatically, [FS41] used the Tree-Traversing Ant (TTA) clustering algorithm to functionally cluster Web services into homogenous service communities. NLP was used to extract features, and NGD and Wikipedia (n° W) were used as similarity measurements.
To accurately discover users desired mashup services, [FS51], [FS52] proposed a method for clustering mashup services based on exploring services document content and network. Data from PW is used where two-level topic model (LDA) is designed to mine the latent functional topics by incorporating relationships among mashup services and their content. The similarity between mashup services calculated using different similarity measures where a combination of k-means and HAC are used to cluster similar mashup services. To improve clustering web services based on their functional properties, [FS55] proposed a method to cluster Web services based on ontology-generation of the extracted terms by focusing on the specific terms than general terms where the specificity of terms are calculated before generating ontology. Ontology relationship and IR-based similarities are used to find the similarities between Web service and cluster them based on HAC. This work used [FS34] approach and enhanced it with their method of ontology-generation based on specific terms. A topic-based clustering method proposed by [FS56] uses augmented LDA model to improve the clustering of web services based on functional properties. Motivated by the lacking of text information, they trains the latent topic information on Web services descriptions using Word2vec where Web services with the same topic are clustered together. The training process done based on clustering similar words from Web services document into similar clusters.
Methods based on clustering for web service recommendation
Table 10 provides a summary of clustering methods for Web service recommendation by stating their algorithms, specifications, datasets used and whether it uses functional or non-functional properties. To overcome the challenge of data sparsity in QoS predication using Collaborative filtering(CF), [FS17] used HAC to cluster services based on their physical environment, measured the similarity of users using Pearson correlation coefficient (PCC) based on the clusters, and then applied CF. [FS20] utilized customer profiles and historical usage experiences of service invocation by using K-means to cluster customers. CF was used to study users' behaviours from a service usage history perspective and then find patterns among Web services in the repository to predict a user's preferences on certain Web services. PCC, cosine and Euclidean distance are used to measure similarity. K-means was also used in [FS11] in a clustering collaborative filtering (CluCF) method by employing users and service clusters using time-aware similarity measures and using the location factor to update clusters. QoS performance and invocation time were used to improve the prediction accuracy. PCC was used to calculate the similarities between users and services.
Most existing approaches ignore the data credibility problem leading to the unreliable QoS data contributed by dishonest users. [FS1] used k-means clustering on historical QoS data to cluster users and services, predict QoS and recommend a service. CF and clustering are used where the service reputation is calculated, similar users are identified, trustworthy users are identified, similar services are identified, and then missing values can be predicted. PCC was used to measure the similarity. To overcome the challenge that historical Web service QoS data are not updatedin real-time leading to low QoS prediction accuracy, [FS40] proposed a landmark-based QoS prediction based on User-Based Clustering (UBC) and Web Service-Based Clustering (WSBC) based on HAC for Web services. Real QoS data from a set of fixed landmarks from Planet Lab and PCC as the similarity measure between two users were used. To increase the performance of QoS prediction and to provide a more personalized recommendation, [FS4] used HAC to cluster users and services based on their locations and QoS data. The system works to predict Web services QoS values and recommend the best one for active users based on historical Web service QoS records using QoS-aware collaborative filtering. PCC is used as a similarity measure between users based on the QoS values of web services they both invoked.
To handle the problem of limited tags attached with Web services, [FS3] proposed a hybrid Web Service Tag Relevance Measurement mechanism (WS-TRM) to measure the relevance of a tag to a Web service by using semantic similarity and tag authority. WSDL features extracted with the tag are calculated using NGD and then integrated with Tag-authority-based Hyperlink-Induced Topic Search (HITS) similarity.WS-TRM is applied in tag recommendation for Web services. Users invoke a few services which lead to many missing QoS values, and the user-service matrix might be sparse, [FS9] [FS26] used k-means to cluster users and services based on their locations in a location-based hierarchical matrix factorization (HFM) method to predict missing QoS values. User-service global context and geographic information were used to build an HFM model-based CF method to predict missing values.
To prevent time-consuming and inaccurate recommendations of semantic Web services for a composite service, [FS21] proposed a method of Clustering and Recommendation for OWL-S Web services in Evolution (CRE) using HAC-based WordNet, TFIDF and cosine similarity measurement and matrix factorization recommendation. Using the historical QoS experiences of similar users to predict a user's QoS on a known Web service, [FS30] used k-means clustering to cluster users and services in a global structure using Relational Clustering-based Model (RCM), a collaborative filtering-based scheme, to evaluate the QoS of a priori unknown service providers. CF is used to predict the QoS of unknown Web services. PCC, WordNet, and cosine are used to measure similarities. Based on the use of heterogeneous features to improve recommendation, [FS46] used k-means to cluster services in a Web Service Heterogonous Feature Selection (WS-HFS) method on heterogeneous data sources of Web services to perform Web service mining. The framework has two components: feature selection and service mining. Features are selected and transformed into knowledge in the feature subspace, and a data source-based weight learning method is proposed.
To increase the performance of Web service selection and recommendation, [FS49] proposed clustering Web service based on their functionalities using HTS [13] based semantic similarities and cluster them again based on their manually assigned QoS values using Spherical Associated Keyword Space (SASKS) algorithms. By not only considering QoS metrics for Web services recommendations, [FS50] proposed a method to include Web services functional properties extracted from WSDL files in addition to QoS metric for Web service recommendations. Fuzzy C-means clustering algorithm is used to cluster user and services where matrix factorization approach used that integrates the functional categories of the Web service. [FS57] proposed an active learning approach for Web service tag recommendation where SVM is trained on labelled Web services to classify unlabelled Web services based previously labelled small set of Web services by a domain expert. By learning the correlations among tags by computing Jaccard and hierarchical clustering based tag correlations, they minimize the efforts of the domain expert using an active learning-binary classification on a service for each possible label to determine if the tag should be recommended to the service.
Methods based on association rules for web service discovery
Table 11 provides a summary of the association rule methods for Web service discovery by stating their algorithms, specifications, datasets used and whether it uses functional or non-functional properties. To infer patterns from service descriptions by providing a summarized and integrated representation of Web service functionality, [FS6] used the Apriori algorithm to extract useful knowledge from a set of datasets based on WSDL files and service invocation. Web service discovery via intentional knowledge mining is a method for extracting a useful intentional representation of Web service repository contents to help application developers learn new knowledge regarding the available service and make the correct choice. Using Web service interfaces when its parameters contains meaningful synonyms, abbreviations and semantic can improve the discovery process, [FS54] propose an approach that mine the underline semantics and conduct semantic extension of Web services interfaces. They mine the underling semantics to create index libraries by using association rules and then clustering interaction interface names and fragment under the supervision of co-occurrence probability.
Methods based on association rules for web service recommendation
Table 12 provides a summary of the association rule methods for Web service recommendation by stating their algorithms, specifications, datasets used and whether it uses functional or non-functional properties. To decide which service among the retrieved set of semantically equivalent Web service candidates is the best, [FS16] used the Apriori algorithm and CF to study users' invocation behaviours from a Web service composition perspective and then use association rules among Web services in the repository to predict users' preferences on certain Web services. User usage patterns are considered, and a profile is generated to provide a personalized ranking for the retrieved set of Web services. For the same purpose, [FS10] used the Apriori algorithm to understand the correlation between users and construct group and individual profiling based on usage history. A group knowledge-based recommendation system using CF is used for ranking and recommendation. By exploring users relations, their history of used services and the quality of services, [FS53] proposed a Web service relationships track (WSR-Track) approach where service ecosystems represented in heterogeneous multigraph. Nodes represent users and services, Edges represent trust/usage relationships between users and services. By incorporating history and QoS data in addition to users, services data association rules is generated and Web service recommendation process provide adequate Web service for users based on tracked relation.
Methods combining clustering/association rules for web service discovery and recommendation
Table 13 provides a summary of the hybrid methods for Web service discovery and recommendation by stating their algorithms, specifications, datasets used and whether it uses functional or non-functional properties. Methods which used clustering for Web service discovery and recommendation, include [FS7] [FS22] where their techniques support both matching (discovery) and selection (recommendation):
Because clustering can boost the power of Web services' search engines and generating tags can improve the search accuracy, [FS7] used k-means clustering and Carrot search clustering to cluster Web services and NLP to extract service features in an automatic tagging for Web services using machine learning. The method extracts relevant tags from a WSDL file and uses co-occurrence to generate tags from a collection of untagged service descriptions files. Cosine similarity is used to measure the similarity between the user query and the content vector of the Web service document. Given the fact that the availability of QoS is important in Web service recommendation and to predict the QoS of non-invoked Web services, [FS22] used NLP to extract features and k-means to cluster similar Web services using semantic LSI and non-semantic approaches. Content-based and Slop one CF were used to predict QoS values and recommend the top-k Web services to users. For similarity, cosine, PCC and TFIDF are used.
Methods which combined clustering and association rules for Web service recommendation, include [FS35] [FS14]. By organizing Web services into similar clusters to reduce the search time, [FS35] used HAC and gain-based association rule classification (GARC) to recommend Web services for the currently invoked service using the proposed cluster-based service recommendation approach. HTS as presented in [FS34], TFIDF, Ontologyand WordNet are used. To reduce the dimensionality of a sparse matrix and solve the cold-start problem in Web service recommendation, [FS14] proposed the User Relationship and Preferences Clustering and Recommendation (URPC-Rec) algorithm to combines users' historical behaviours and their personal interests to perform personal service recommendation for new users. The method combined a defined clustering algorithm and a recommendation algorithm based on finding an association between users and services. User interest tags and social network relationships and information are used where WordNet is used to measure the similarity in the recommendation.
Method combined clustering and association rules for discovery: To overcome the problem where Web service discovery given non-explicit semantic based on service description to match a specific user request, [FS33] used HAC for clustering and Hyperclique patterns to find association in an integrated method for semantic Web service discovery, which relies on semantic Web service categorization and semantic Web service selection. The method utilizes WSDL descriptions and adds semantics using the WordNet database and Suggested Upper Merged Ontology (SUMO) mapping. The selection process relies on the use of LSI and finds the association between permeants in a cluster.
Method combined both clustering and association rules for Web service discovery and recommendation: [FS2] used the K-means clustering algorithm to cluster Web services and association rules for tag recommendation. They used NLP to extract the features from a WSDL document and add tags as another feature. A Web service tag recommendation strategy was proposed to overcome the limitations of noise and uneven distribution of tags where association rules are used to extract the association using training and testing datasets.
Algorithms for Web service discovery and recommendation (RQ1)
The clustering and association rule algorithms used by the researcher to facilitate the process of Web service discovery and recommendation are outlined in Table 14. The partition-based clustering method K-means is the most-used clustering algorithm with 42% of the final selected papers. The algorithm receives the number of clusters as an input, and then finds the centers of clusters using an iterative algorithm. It assigns points to each center based on the distance (similarity) of points to the center of clusters [25-65]. This was followed by the HAC algorithm which appeared in 36% of the final selected papers. Hierarchical agglomerative clustering treat each single document as a cluster and merge pairs of clusters based on similarities until all clusters are merged into a single cluster that contains all documents [66]. Bio-inspired clustering methods [67] were used to cluster Web services in [FS13] using a neural network, [FS23] used particle swarm optimization, and [FS41] used the tree-traversing ant algorithm. The quality threshold clustering algorithm is another partition-based clustering algorithm used in [FS45] and [FS24]. Density-based clustering (DBSCAN) was used in [FS5] The self-organizing-based clustering algorithm was used in [FS31] A relational database (RDB), which is a self-join clustering algorithm, was used in [FS38] Among the final selected papers, clustering algorithms dominated and were more popular when comparing the association rule algorithms. For association rule algorithms, the well-known Apriori algorithm [68] with 43% was used in [FS16], [FS10] and [FS6] to find the association between different variables to meet the research objectives.
Similarity measures for Web service discovery and recommendation (RQ1)
Similarity measures used in the final selected papers for the purpose of Web service discovery and recommendation are listed in Table 15. Used similarity measures can be classified into:
• Semantic-based similarity measurements: These measurements include WordNet, NGD, Wikipedia, and Ontology. WordNet [69] is a lexical database that groups English words into sets of synonyms and records various semantic relations between these synonym sets. Eighteen per cent of the final selected papers used WordNet where the similarity measure based on the structured knowledge base, and edge-based method mostly used. NGD [70] is computed by the Google Web search engine to measure semantic similarity and relatedness between words and recently stated as search engine similarity. Wikipedia was used as a knowledge base semantic similarity measure in [FS41]. Ontology using logic-based reasoning was used in matchmaking and semantic similarity measurement for Web services in [FS43], [FS15], [FS34], [FS35], [FS27], [FS38], [FS29], [FS18], [FS31], [FS5], and [FS23].
• Syntactic-based similarity measurements: These measurements include IR and NLP techniques for measuring similarities in Web service discovery and recommendation. TFIDF is a text mining method used mostly in feature extraction process. It measures the importance of words in a document. TFIDF was used in [FS43], [FS15], [FS35], [FS27], [FS37], [FS19], [FS39], [FS2], [FS21], [FS48], [FS13], [FS22], [FS25] and [FS42]. This is approximately 20% of the final selected papers. Cosine similarity was used to measure the similarity between two documents in the vector space by calculating the cosine of their angle. Cosine similarity was used in [FS7], [FS33], [FS25], [FS20], [FS30], [FS48], [FS28], [FS13], [FS21], and [FS42].
• Distance-based similarity measurements: These measurements were used to measure the similarity between Web services, including Levenshtein distance (LD), Euclidean distance, Mahalanobis distance, and Jaccard coefficient. LD is used to measure the similarity between two strings. The distance is the number of deletions, insertions, or substitutions required to transform one string into another [71], as in [FS43]. The Euclidean distance was used to measure the distance between two vectors in [FS20], [FS42] and [FS28] Mahalanobis distance was used in [FS13] the Jaccard coefficient was used in [FS2] The PCC was used mostly to find the correlation and similarity for Web service recommendation. PCC measures the linear correlations between two variables. It has been used in [FS16], [FS1], [FS17], [FS4], [FS20], [FS10], [FS30], [FS711], [FS22], and [FS40].
• Hybrid-based similarity measurements: These measurements are used by combining semantic similarity measurement, syntactic-based similarity measurements, or distance-based similarity measurements. For example, [FS43] combined WordNet, NGD, and ontology as semantic similarity measures, TFIDF as IR-based syntactic similarity measurements, and LD as distance-based similarity measures. Hybrid-based similarity measures are the most-used measurements. They provide a better solution by integrating different similarities.
• Based on the algorithms and the similarity measures used in the final selected papers, Table 16 discusses the most-used algorithms, linking them to the similarity measures used. Furthermore, it shows gaps that the proposed methods did not investigate. For example, it indicates that a combination of using HAC with the semantic similarity measure WordNet is one of the most-used techniques in the proposed methods. It also indicates that HAC is not used with the NGD semantic similarity measure.
Evaluation metrics used for Web service discovery and recommendation (RQ1)
The evaluation metrics used in the final selected papers to validate and evaluate the proposed Web service discovery and recommendation approaches are outlined in Table 17. Knowing the evaluation metrics used to evaluate the proposed methods helps researchers in comparing their results to those of other studies. Evaluation metrics had individual purposes to measure depending on the context of use. For example, the table shows that recall and precision are the most used evaluation metrics to measure the performance of the proposed methods comparing to the other evaluation metrics.
Datasets used for Web service discovery and recommendation (RQ2)
The final selected papers used various datasets to validate and evaluate proposed Web service discovery or recommendation solutions. These data sets vary based on the method of collection. Some researchers gathered and captured their datasets from famous Web service repositories. Other researchers tested their solution based on publicly published benchmarks. We categorized Web service datasets based on the method of collection into self-gathered and published benchmarks. Self-gathered datasets refer to Web service datasets collected, captured, and crawled from different Web service repositories over the Internet for validation self-use. Some researchers share their collected Webservice datasets. For self-gathering of Web service datasets, researchers used several websites to capture and crawl Web services. These included Seekdac, PWd, WebserviceXe, WebserviceListf, xMethodsg, Salcentral, and Titan Search Engine. However, some of the websites are no longer available, including Seekda, Webservice List, Salcentral, and xMethods.
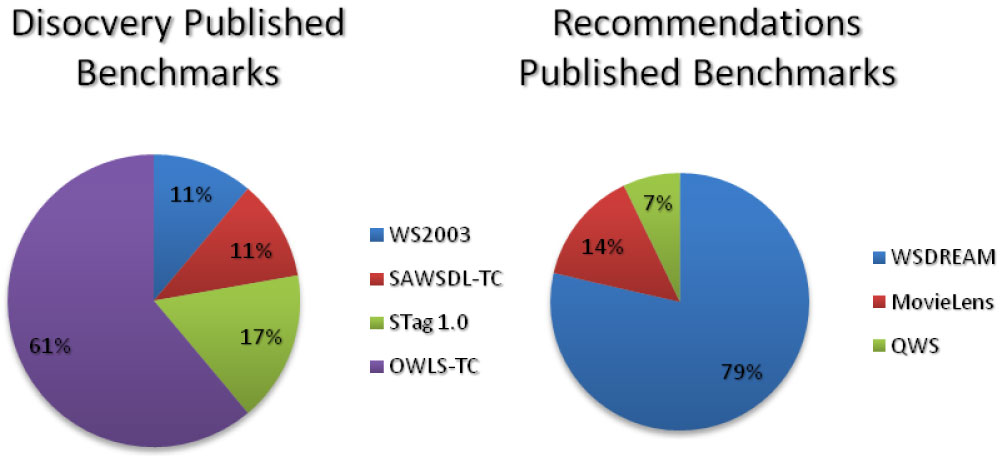
The existence of published benchmarks helps researchers validate their solutions without the need to collect Web services. In the final selected papers, Web services' published benchmarks have been used more than self-gathered Web services'. Table 18 outlines and details eight Web services' published benchmarks. The current locations of the used published benchmarks are also indicated in the table. [FS25] and [FS42] used a WSDL-based published benchmark named WS2003 for discovery purposes. WS2003 [72] used it for annotation of Web services using machine learning with WSDL files gathered from Salcentral and XMethods. [FS8] and [FS23] used a semantic-based published benchmark named SAWSDL-TC for Web service discovery. [FS3], [FS46], and [FS2] used a WSDL-based dataset annotated with user tags named STag 1.0 for discovery purposes. [FS18], [FS37], [FS38], [FS29], [FS5], [FS47], [FS48], [FS31], and [FS6] used a semantic-based published benchmark named OWLS-TC for Web service discovery. WS2003, SAWSDL-TC, STag 1.0, and OWLS-TC are published benchmarks and test collections that have been used in the final selected papers for discovery purposes. For Webservice recommendation, [FS1], [FS17], [FS4], [FS26], [FS9], [FS30], [FS11], [FS14], and [FS40] used the Web service QoS dataset named WS-DREAM. [FS10] and [FS14] adopted the famous movies recommendation dataset Movie Lens and [FS22] used the quality of Web service (QWS) dataset for Web service recommendation. Figure 10 illustrates the usage of published benchmarks in the final selected papers.
Table 19 outlines the methods for Web service collection, types of datasets, and nature of datasets used in the final selected papers. Fifty-sixper cent of the final selected papers used known published benchmarks to validate their proposed solutions. Alternately, 44% of the final selectedpapers used self-gathering to collect Web service datasets for validation purposes. The type of Web service datasets can be syntax, semantic, or both. Based on the DL used, researchers tend to use syntax-based Web services more than semantic-based ones to validate and test their solutions. However, some researchers used both syntax and semantics to validate their work. The nature of Web service datasets can be from real-world Web services, synthetic datasets for validation purposes only, or a combination of both real and synthetic. Real-world Web service datasets are used more by researchers compared to other types.
Web service discovery and recommendation trends and future directions (RQ3)
The last decade witnessed the growth of Web services as providers developed and published an enormous number of Web-based services. This made it a challenge to discover services in a broad and diverse Web service space. The discovery problem is inherently difficult because of the large-scale SOA systems, including Web services, mobile services, cloud services, and cloud computing. These services are dynamic, changing, and uncertain in nature. The scope of services in SOA is changing rapidly as new services are addedand old ones are deleted or modified. New standards emerge as old ones are abandoned by developers. Web service discovery and recommendation methods and techniques proposed by researchers have been applied separately rather than working in parallel. Web service discovery (matching) and Web service recommendation (selection and ranking) need to be integrated to better understand user requirements in locating the right Web services. Previous approaches separated Web service discovery from Web service recommendation. We argue that the cause of this is the need to find the right Web service datasets to apply both discovery and recommendation to. However, matching and selecting the right Web services should be considered together and in parallel in this process. Another gap is the use of one type of similarity measure to find similar Web services in the process of Web service clustering or discovery. The limitations of syntactic-based similarity measure can be overcome or minimized if combined with another similarity measure, such as distance, semantic, or context similarity.
Clustering techniques can be used to reduce the search space when looking for the right Web services. However, it can be time-consuming to cluster Web services based on different similarities. New parallel and distributed data processing tools and techniques (e.g., Apache Hadoop) can be used to group Web services and increase or enhance clustering speed. One example is its use in the k-means parallel clustering algorithm to address Web service discovery and prediction problems with big data circumstances. Another gap is found in achieving a domain-specific Web service clustering while considering users and service context. The performance of Web service clustering can be improved with additional features and Web service information. As an example, Web service tag information can be utilized to improve the performance of Web service clustering. Most of the proposed approaches investigate offline Web service clustering. Real-time or online Web service clustering provides a better solution and current Web service information. QoS parameters are an important aspect of the process of Web service ranking, selection, and recommendation. This is not considered in major Web service discovery works. Detecting malicious and outlier users with inaccurate QoS information and noise QoS improves prediction. Finding a complete solution for Web service discovery and recommendation starting with user query to matching and retrieving the requested Web service and finally selecting and ranking Web service is rare to find in such an environment where most proposed solutions have enhanced just one part of the overall process. Finding a complete Web service discovery and recommendation system in more detail is a gap. Semantic-based Web service approaches need to provide service requestors with step-by-step semantically guided methods to locate the target Web service components to minimize the complexity.
We have identified three areas of trends and future directions for Web service discovery and recommendation. Table 20 outlines the three areas and the challenges to be addressed:
• Comprehensive and Neutral Web Service Discovery and Recommendation: The discovery process of Web services focuses on WSDL-based or semantic-based Web services, neglecting the fact that most Web services are described in plain text. Web service discovery approaches should extend their methods to be comprehensive and neutral to work with any Web service description. Most Web services (Web APIs) are described in plain text. Therefore, NLP, text and DM, IR, collaborative tagging, and service information extraction techniques can be used to identify useful patterns, clusters, and group-related Web services and extract useful semantics without focusing on particular form of web services description language.
• Social Network Web Service Discovery and Recommendation: Web service discovery and recommendation can be enhanced using social network data to detect hidden relationships between services and users to generate recommendations. Information and interactions can improve the process of Web service discovery and recommendation by utilizing social network data through user activities. For example, user experiences, ratings, questions, and feedback posted on the social network regarding Web services or any other topics can provide a better understanding of user requirements. Social network and network analysis tools and techniques can boost and improve the discovery and recommendation of Web services.
• Big Data Analytics-driven Web Service Discovery and Recommendation: There are limitations to the proposed Web service discovery and recommendation approaches. These can be overcome by using big data analytics tools and techniques. Clustering Web service approaches can benefit from running the parallel clustering algorithm to speed up the process of clustering. Furthermore, online Web service discovery and recommendation provide a new research direction to take advantage of the development of algorithms and models for processing data online in big data ecosystems. It provides a way to develop more scalable and adaptable discovery and recommendation solutions in a large-scale and changing environment.
Discussion
Web services discovery and recommendation methods have been proposed in different studies using various techniques to facilitate the process of web service selection and invocation for users. By analyzing the final selected papers, we found that most approaches focus exclusively on either functional or non-functional clustering of web services, and that there is a dearth of research that combines these two properties. A possible reason could be due to the fact that combining both functional and non-functional properties in the clustering process may increase complexity. One of the challenges in building web services discovery and recommendation solutions is finding the right web services datasets that meet the requirements of the proposed method. Some proposed methods use real web services dataset to test their solution, others had to add synthetic data to meet the required set of input for their proposed solution. The existence of new web services datasets and collection benchmarks can help the community produce web service discovery and recommendation solutions, and test and compare their results with other solutions. In general, syntactic based approaches, where syntactic similarity measures are used, provide a straightforward solution with low performance, contrary to semantic-based approaches, where semantic measures are used, which provide a more complex solution with better performance. Hybrid based approaches, which combine both syntactic and semantic similarity measures, provide a better solution with high performance in finding web services. However, complexity and processing time will be increased.
In terms of implications for research, we provide a synthesis on the current proposed methods for web service discovery and recommendation based on systematic procedures. We contribute to the theory of web service discovery and recommendation by providing a classification of the approaches employed based on the selected paper. Furthermore, we provide a list of algorithms for clustering and association rules, similarity measures, and evaluation metrics. This provides future researchers with insights on algorithms, similarity measures, and evaluation metrics used, and the gaps for future research. Moreover, we identified the most used datasets for web service discovery and recommendation with their locations and classified web service datasets based on their types, methods of collection and their nature. Finally, we identified the trends and future directions for web services discovery and recommendations.
In terms of implication for practice, finding a complete solution for web service discovery and recommendation, which starts with users sending a query to match, retrieve, and finally select and rank the list of matched web services, is rare to find in the proposed solutions. However, a complete solution that provides a combination of web service discovery and recommendations methods can be exist in practice in a real working environment. This solution should be able to understand the user's requirements from both functional and non-functional perspectives and incorporate the requirements into a discovery and recommendation solution. The solution should be able to analyze the user requirements and match against the list of services. Based on our SLR, to overcome the limitation of short description of web service (with too little words), and to improve clustering performance, we suggest the use of semantic extensions and extraction techniques, in addition to adding extra words in the web services datasets during the preprocessing step. Furthermore, the use of users' data from social networks will add more information about service users, which will reflect in finding the correlation between service users, their patterns and context. The use of big data analytics tools and techniques such as Hadoop and Spark can improve the performance of clustering and speed up the processing time.
Threats to Validity
This SLR provides a classification of clustering and association rule techniques for web service discovery and recommendation. It identifies methods, algorithms, similarity measures and evaluation metrics. The review was carried out to provide the current state-of-the-art information in the area of clustering and association rules for web service discovery and recommendation based on systematic procedures. The focus was finding answers to predefined research questions from the final selected papers. We identified 57 final selected papers with specific quality requirements. We extracted the data to answer the research questions, and we believe that significant work remains to improve the current state of research in the area of clustering and association rules for web service discovery and recommendation. However, validity is a primary concern in such empirical studies. We discuss the limitations to construct, internal, and external validities [73].
Construct validity looks at whether the implementation of SLR matches the initial objectives. We identify the search and selection processes as possible limitations. Search terms and keywords were derived from the population and intervention used in forming the research questions. They were tested against a well-known list of research studies. However, the completeness and thoroughness of the terms are not assured. To mitigate the risk, we snowballed the references of the list of selected studies. The search identified two studies in the Chinese language, which were excluded. Additionally, 10 studies were excluded because we were unable to access the full text. This may present a threat to construct validity. Although well-known digital libraries were used to search for the selected studies, other digital libraries may contain relevant studies that have not been taken into consideration.
Internal validity is the extent to which the design and conduct of the study can prevent systematic error and work as a prerequisite for external validity [1]. Some concerns about data extraction are worth highlighting here. In the process of data extraction from the final selected studies, we rely on our interpretation and analysis when necessary data are not clearly stated. Some of the required data in the process of extraction were missing in the final selected studies. This may potentially affect the internal validity of the study.
External validity is the extent to which the effects observed in the study are applicable outside [1]. It is about the generalizability and applicability of the study outcomes. The research questions and quality assessment reduced the risk of generalizability of the outcomes. Furthermore, the SLR is focused on being controlled by a focus problem related to clustering and association rule techniques for web service discovery and recommendation. This was at a predefined time (2006-2017), and the problem was not previously investigated. When considering this information, we consider the outcome of the SLR to be generalizable and applicable. It is worth noting that all steps for this SLR including the discussions and decisions about the SLR search and selection protocols were done collaboratively among the authors. None of the final selected papers were co-authored by us or by anyone related to our affiliations. The research questions were designed while multiple authors provided their feedback to improve the final research questions. The search query was resolved collaboratively while each author verified the results. Furthermore, the development of the inclusion and exclusion criteria was conducted collaboratively, and conflicts were resolved by discussion.
Conclusions
The reported SLR provides a classification of clustering and association techniques for Web service discovery and recommendation, and it identifies methods, algorithms, similarity measures, datasets and evaluation metrics. The review was carried out to provide the current state-of-the-art in the area of clustering and association rules for Web service discovery and recommendation based on systematic procedures. The focus was finding answers to the predefined research questions from the final selected papers. We identified 57 final selected papers with specific quality requirements and extracted data to answer the research questions. Our SLR reveals that clustering techniques are the most in the literature and have been mostly usedfor Web service discovery. As such, there is a dearth of academic literature where association rules techniques have been used for Web service discovery and recommendation. Furthermore, K-means and HAC are the most common clustering algorithms, and most studies have used these techniques in combination with semantic or syntactic similarity measures. We believe that much work remains to improve the current state of research in the area of clustering and association rules for Web service discovery and recommendation. Future studies should investigate online live Web services which broaden the basis of discovery and recommendation by including various type of Web service descriptions including plain text description that are currently used in Web APIs. There is also an opportunity to improve Web service discovery and recommendation by utilizing modern techniques based on big data analytics and social network analysis. Lastly, future research could also benefit from harvesting current and generating new Web service description datasets for benchmarking and evaluating Web services discovery and recommendation solutions.
References
- B Kitchenham, S Charters (2007) Guidelines for performing systematic literature reviews in software engineering.
- K Hashmi, A Alhosban, Z Malik, et al. (2014) Automated negotiation among web services. In: Web Services Foundations, Springer, New York, 451-482.
- M Crasso, A Zunino, M Campo (2008) Easy web service discovery: A query-by-example approach. Sci Comput Program 71: 144-164.
- LD Ngane, A Goh, CH Tru (2008) A Survey of web service discovery systems. In: GI Alkhatib, DC Rine, IGI Global.
- M Klusch (2014) Service discovery. Encycl Soc Networks Min. In: R Alhajj J Rokne, Springer.
- Garofalakis J Panagis, Y Sakkopoulos, E Tsakalidis (2004) Web service discovery mechanisms: Looking for a needle in a haystack?. International Workshop on Web Engineering 5: 265-290.
- M Zhang, X Liu, R Zhang, et al. (2012) A web service recommendation approach based on qos prediction using fuzzy clustering. In: IEEE Ninth International Conference on Services Computing 138-145.
- DN Le, AE Soong Goh (2007) A survey of web service discovery systems. Int J Inf Technol. Web Eng 2: 65-80.
- E Newcomer (2002) Understanding web services: XML, Wsdl, Soap, and UDDI. Addison-Wesley Professional.
- WJ Obidallah, B Raahemi (2017) A survey on web service discovery approaches. In: Proceedings of the Second International Conference on Internet of things and Cloud Computing - ICC 17: 1-8.
- W Liu, W Wong (2009) Web service clustering using text mining techniques. Int J Agent-Oriented Softw Eng 3.
- K Elgazzar, AE Hassan, P Martin (2010) Clustering WSDL documents to bootstrap the discovery of web services. In: EEE International Conference on Web Services, 147-154.
- BTGS Kumara, I Paik, THAS Siriweera, et al. (2016) Cluster-based web service recommendation. In: IEEE International Conference on Services Computing (SCC), 348-355.
- P He, J Zhu, J Xu, et al. (2014) A hierarchical matrix factorization approach for location-based web service qos prediction. In: IEEE 8th International Symposium on Service Oriented System Engineering, 290-295.
- X Chen, Z Zheng, Q Yu, et al. (2014) Web service recommendation via exploiting location and qos information. In: IEEE Trans Parallel Distrib Syst 25: 1913-1924.
- J Zhu, Y Kang, Z Zheng, et al. (2012) A clustering-based qos prediction approach for web service recommendation. In: 2012 IEEE 15th International Symposium on Object/Component/Service-Oriented Real-Time Distributed Computing Workshops, 93-98.
- B Kitchenham (2004) Procedures for performing systematic reviews. In: Keele, UK, Keele Univ, 33: 28.
- B Kitchenham, O Pearl Brereton, D Budgen, et al. (2009) Systematic literature reviews in software engineering - A systematic literature review. Inf Softw Technol 51: 7-15.
- T Dyba, T Dingsoyr (2008) Empirical studies of agile software development: A systematic review. Inf. Softw Technol 50: 833-859.
- Z Cong, A Fernandez, H Billhardt, et al. (2015) Service discovery acceleration with hierarchical clustering. Inf Syst Front 17: 799-808.
- J Wu, L Chen, Z Zheng, et al. (2014) Clustering Web services to facilitate service discovery. Knowl Inf Syst 38: 207-229.
- https://www.covidence.org/home.
- http://www.core.edu.au/home.
- Clarivate Analytics (2017) 2015 Journal Citation Reports.
- G Tian, J Wang, K He, et al. (2016) Leveraging auxiliary knowledge for web service clustering. Chinese J Electron 25: 858-865.
- G Tian, C Sun, K qing He, et al. (2016) Transferring auxiliary knowledge to enhance heterogeneous web service clustering. Int J High Perform Comput Netw 9: 160.
- Sowmya Kamath S, Ananthanarayana VS (2014) Similarity analysis of service descriptions for efficient Web service discovery. In: International Conference on Data Science and Advanced Analytics (DSAA), 142-148.
- QQ Yu, HH Wang, LL Chen (2015) Learning sparse functional factors for large-scale service clustering. In: IEEE International Conference on Web Services, 201-208.
- BTGSTGS Kumara, I Paik, G Lee (2012) Ontology learning method for Web services clustering. In: Proceedings - 2012 7th International Conference on Computing and Convergence Technology (ICCIT, ICEI and ICACT), ICCCT, 705-710.
- B Upadhyaya, F Khomh, Ying Zou, et al. (2012) A concept analysis approach for guiding users in service discovery. In: Fifth IEEE International Conference on Service-Oriented Computing and Applications (SOCA), 1-8.
- J Ma, Y Zhang, J He (2008) Web services discovery based on latent semantic approach. In: IEEE International Conference on Web Services, 740-747.
- M Aznag, M Quafafou, Z Jarir (2014) Leveraging formal concept analysis with topic correlation for service clustering and discovery. In: IEEE International Conference on Web Services, 153-160.
- J Ma, Y Zhang, J He (2008) Efficiently finding web services using a clustering semantic approach. In: Proceedings of the 2008 international workshop on Context enabled source and service selection, integration and adaptation organized with the 17th International World Wide Web Conference (WWW 2008) - CSSSIA '08, 292, 1-8.
- T Wen, G Sheng, Y Li, et al. (2011) Research on Web service discovery with semantics and clustering. In: 6th IEEE Joint International Information Technology and Artificial Intelligence Conference, 1: 62-67.
- K Elgazzar, HS Hassanein, P Martin (2014) DaaS: Cloud-based mobile web service discovery. Pervasive Mob Comput 13: 67-84.
- BTGS Kumara, I Paik, H Ohashi, et al. (2014) Context aware post-filtering for web service clustering. In: IEEE International Conference on Services Computing, 440-447.
- BTGS Kumara, I Paik, W Chen, et al. (2014) Web service clustering using a hybrid term-similarity measure with ontology learning. Int J Web Serv Res 11: 24-45.
- BTGS Kumara, I Paik, KRC Koswatte, et al. (2014) Ontology learning with complex data type for Web service clustering. In: IEEE Symposium on Computational Intelligence and Data Mining (CIDM), 129-136.
- S Dasgupta, S Bhat, Y Lee Taxonomic (2011) Clustering and query matching for efficient service discovery. In: IEEE International Conference on Web Services, 363-370.
- T Liang, L Chen, H Ying, et al. (2014) Co-Clustering wsdl documents to bootstrap service discovery. In: IEEE 7th International Conference on Service-Oriented Computing and Applications, 215-222.
- J Liu, F Liu, X Li, et al. (2015) Web service clustering using relational database approach. Int J Softw Eng Knowl Eng 25: 1365-1393.
- C Platzer, F Rosenberg, S Dustdar (2009) Web service clustering using multidimensional angles as proximity measures. ACM Trans Internet Technol 9: 1-26.
- JM Rodriguez, A Zunino, C Mateos, et al. (2015) Improving REST service discovery with unsupervised learning techniques. In: 2015 Ninth International Conference on Complex, Intelligent, and Software Intensive Systems, 97-104.
- Nagy C Oprisa, I Salomie, CB Pop, et al. (2011) Particle swarm optimization for clustering semantic web services. IN: 10th International Symposium on Parallel and Distributed Computing, 170-177.
- L De Jesus Silva, DB Claro, DCP Lopes (2015) Semantic-based clustering of web services. J Web Eng vol 34: 325-345.
- F Chen, M Li, H Wu, et al. (2017) Web service discovery among large service pools utilising semantic similarity and clustering. Enterp Inf Syst 11: 452-469.
- H Gao, S Wang, L Sun, et al. (2014) Hierarchical clustering based web service discovery. In: IFIP Advances in Information and Communication Technology, 426: 281-291.
- L Chen, G Yang, W Zhu, et al. (2013) Clustering facilitated web services discovery model based on supervised term weighting and adaptive metric learning. Int J Web Eng Technol 8: 58.
- F Chen, S Yuan, B Mu (2015) User-QoS-based web service clustering for qos prediction. In: IEEE International Conference on Web Services, 583-590.
- R Liu, X Xu, Z Wang (2015) Service recommendation using customer similarity and service usage pattern. In: IEEE International Conference on Web Services, 408-415.
- Yu L Huang (2017) CluCF: A clustering CF algorithm to address data sparsity problem. Serv Oriented Comput Appl 11: 33-45.
- K Su, B Xiao, B Liu, et al. (2017) TAP: A personalized trust-aware QoS prediction approach for web service recommendation. Knowledge-Based Syst 115: 55-65.
- L Chen, J Wu, Z Zheng, et al. (2014) Modeling and exploiting tag relevance for Web service mining. Knowl Inf Syst 39: 153-173.
- P He, J Zhu, Z Zheng, et al. (2014) Location-based hierarchical matrix factorization for web service recommendation. In: IEEE International C onference on Web Services, 297-304.
- Y Lei, Z Jiantao, Z Junxing, et al. (2015) Time-Aware semantic web service recommendation. In: IEEE International Conference on Services Computing, PG-664-671, 664-671.
- Q Yu (2014) QoS-aware service selection via collaborative QoS evaluation. World Wide Web, 17: 33-57.
- L Chen, Q Yu, PS Yu, et al. (2015) WS-HFS: A heterogeneous feature selection framework for web services mining. In: IEEE International Conference on Web Services, 193-200.
- Bianchini P Garza, E Quintarelli (2016) Characterization and search of web services through intensional knowledge. J Intell Inf Syst 47: 375-401.
- W Rong, K Liu, L Liang (2009) Personalized web service ranking via user group combining association rule. In: IEEE International Conference on Web Services, 445-452.
- W Rong, B Peng, Y Ouyang, et al. (2015) Collaborative personal profiling for web service ranking and recommendation. Inf Syst Front 17: 1265-1282.
- M Lin, DW Cheung (2014) Automatic tagging web services using machine learning techniques. In: IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), 2: 258-265.
- G Vadivelou, E Ilavarasan (2014) Collaborative filtering based hybrid approach for web service recommendations. Res J Appl Sci Eng Technol 8: 615-622.
- M Gong, Z Xu, L Xu, et al. (2013) Recommending web service based on user relationships and preferences. In: IEEE 20th International Conference on Web Services, 380-386.
- VV Paliwal, B Shafiq, J Vaidya, et al. (2012) Semantics-based automated service discovery. IEEE Trans Serv Comput 5: 260-275.
- J MacQuee (1967) Some methods for classification and analysis of multivariate observations. In: Proceedings of the fifth Berkeley symposium on mathematical statistics and probability 1: 281-297.
- S Everitt, S Landau, M Leese, et al. (2011) Hierarchical Clustering. In: Cluster Analysis, 71-110.
- SJ Nanda, G Panda (2014) A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm Evol Comput 16: 1-18.
- H Toivonen (2017) Apriori algorithm. Encyclopedia of Machine Learning and Data Mining.
- Ga Miller (1995) WordNet: A lexical database for English Commun. ACM 38: 39-41.
- RL Cilibras, PMB Vitanyi (2007) The google similarity distance. IEEE Trans Knowl Data Eng 19: 370-383.
- VI Levenshtein (1966) Binary codes capable of correcting deletions, insertions, and reversals. Sov Phys Dokl 10: 707-710.
- Heb, N Kushmerick (2004) Machine learning for annotating semantic web services. In: AAAI Spring Symposium on Semantic Web Services.
- Wohlin P Runeson, M Host, MC Ohlsson, et al. (2012) Experimentation in Software Engineering, Springer, Berlin, Heidelberg.
Corresponding Author
Waeal J Obidallah, Researcher at Knowledge Discovery and Data Mining Lab, Telfer School of Management, University of Ottawa, DMS-6156 - 55, Laurier Ave. East, Ottawa, ON, K1N 6N5, Ext 4613, Canada, Tel: 613-562-5800.
Copyright
© 2019 Obidallah WJ, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.